
Một nhóm con hợp lý là một nhóm các phép đo được tạo ra trong cùng một tập hợp các điều kiện. Các nhóm con được thiết kế để thể hiện một bức tranh tổng quan về quy trình của bạn. Do đó, các phép đo tạo nên một nhóm con nên được thực hiện từ cùng một thời điểm. Ví dụ: nếu bạn lấy mẫu 5 sản phẩm mỗi giờ, quy mô nhóm con của bạn sẽ là 5.
.png "Thống kê năng lực quy trình: Cpk so với Ppk trong minitab")
Công thức, định nghĩa, v.v.
Mục tiêu của phân tích năng lực là đảm bảo một quy trình có khả năng đáp ứng các yêu cầu của khách hàng, và chúng tôi sử dụng các thống kê năng lực như Cpk và Ppk để đánh giá điều đó. Nếu xem xét các công thức Cpk và Ppk cho năng lực quy trình chuẩn (phân phối chuẩn), chúng ta có thể thấy chúng gần như giống hệt nhau:
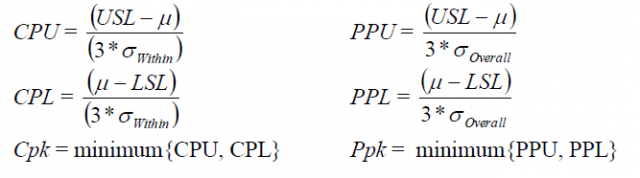
Sự khác biệt duy nhất nằm ở mẫu số của thống kê Trên và Dưới: Cpk được tính bằng độ lệch chuẩn TRONG, trong khi Ppk sử dụng độ lệch chuẩn TỔNG THỂ. Để tránh làm bạn nhàm chán với các chi tiết xung quanh công thức tính độ lệch chuẩn, hãy coi độ lệch chuẩn trong là trung bình của độ lệch chuẩn nhóm con, trong khi độ lệch chuẩn tổng thể biểu thị sự biến thiên của tất cả dữ liệu. Điều này có nghĩa là:
Cpk:
- Chỉ tính đến sự thay đổi TRONG các nhóm con
- Không tính đến sự thay đổi và trôi dạt giữa các nhóm phụ
- Đôi khi được gọi là khả năng tiềm ẩn vì nó thể hiện tiềm năng mà quy trình của bạn có thể sản xuất các bộ phận trong phạm vi thông số kỹ thuật, giả sử không có sự khác biệt giữa các nhóm con (tức là theo thời gian)
Ppk:
- Tính đến sự thay đổi TỔNG THỂ của tất cả các phép đo được thực hiện
- Về mặt lý thuyết bao gồm cả sự thay đổi trong các nhóm con cũng như sự dịch chuyển và trôi dạt giữa chúng
- Là nơi bạn đang ở vào cuối ngày
Ví dụ về sự khác biệt giữa Cpk và Ppk
Để minh họa, chúng ta hãy xem xét một tập dữ liệu trong đó 5 phép đo được thực hiện mỗi ngày trong 10 ngày.
Ví dụ 1 - Cpk và Ppk tương tự
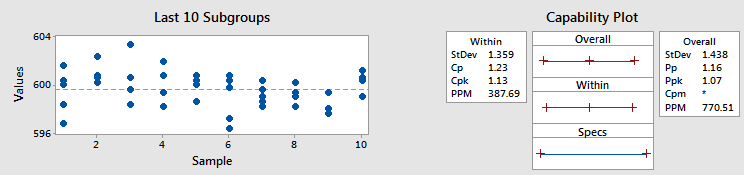
Như biểu đồ bên trái cho thấy, không có nhiều sự dịch chuyển và trôi dạt giữa các nhóm con so với sự biến thiên trong chính các nhóm con đó. Do đó, độ lệch chuẩn trong và độ lệch chuẩn tổng thể tương tự nhau, nghĩa là Cpk và Ppk cũng tương tự nhau (lần lượt là 1,13 và 1,07).
Ví dụ 2 - Cpk và Ppk khác nhau
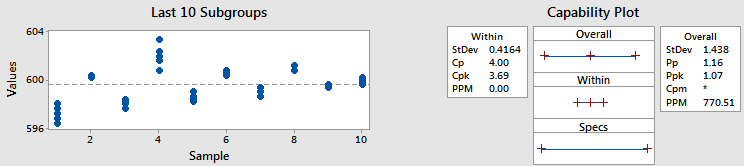
Trong ví dụ này, tôi sử dụng cùng dữ liệu và quy mô nhóm con, nhưng tôi đã dịch chuyển dữ liệu, chuyển nó vào các nhóm con khác nhau. (Tất nhiên, trên thực tế, chúng ta không bao giờ muốn chuyển dữ liệu vào các nhóm con khác nhau – tôi chỉ làm điều đó ở đây để minh họa một điểm.)
Vì chúng tôi sử dụng cùng một dữ liệu, độ lệch chuẩn chung và Ppk không thay đổi. Nhưng điểm tương đồng chỉ dừng lại ở đó.
Hãy xem thống kê Cpk. Nó là 3,69, tốt hơn nhiều so với 1,13 mà chúng ta đã có trước đó. Nhìn vào biểu đồ nhóm con, bạn có thể cho biết tại sao Cpk lại tăng không? Biểu đồ cho thấy các điểm trong mỗi nhóm con gần nhau hơn nhiều so với trước đây. Trước đó tôi đã đề cập rằng chúng ta có thể coi độ lệch chuẩn trong nhóm con là trung bình của các độ lệch chuẩn trong nhóm con. Vì vậy, độ biến thiên trong mỗi nhóm con nhỏ hơn tương đương với độ lệch chuẩn trong nhóm con nhỏ hơn. Và điều đó cho chúng ta Cpk cao hơn.
Ppk hay không Ppk
Và đây chính là điểm nguy hiểm khi chỉ báo cáo Cpk mà quên mất Ppk như thể nó là bạn cùng nhóm nhạc ít được biết đến của George Michael (không có ý xúc phạm bất kỳ ai). Chúng ta có thể thấy từ các ví dụ trên rằng Cpk chỉ cho chúng ta biết một phần câu chuyện, vì vậy lần tới khi bạn xem xét khả năng của quy trình , hãy xem xét cả Cpk và Ppk của bạn. Và nếu quy trình ổn định với ít biến động theo thời gian, thì dù sao thì hai thống kê này cũng sẽ gần như giống nhau.
(Lưu ý: Có thể, và được, để có được Ppk lớn hơn Cpk, đặc biệt là với kích thước nhóm con là 1, nhưng tôi sẽ để lại lời giải thích cho một ngày khác.)
.png)