Sau đây là một tình huống liên quan đến khả năng xử lý mà chúng tôi thỉnh thoảng gặp phải trong bộ phận hỗ trợ kỹ thuật của Minitab. Tôi chia sẻ chi tiết trong bài viết này để bạn biết cần tìm kiếm ở đâu nếu gặp phải tình huống tương tự.
Bạn cần chạy phân tích năng lực. Bạn tạo kết quả bằng Phần mềm Thống kê Minitab . Khi xem kết quả, Cpk rất lớn và biểu đồ histogram trong kết quả trông lạ:
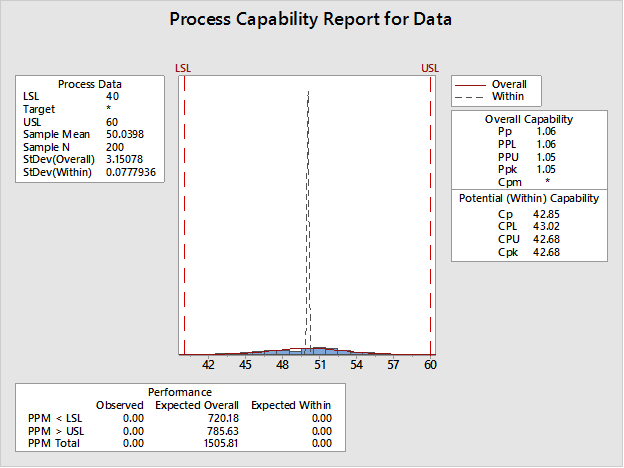
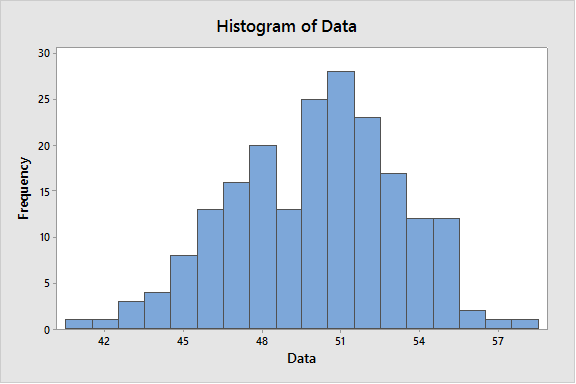
Chuyện gì đang xảy ra ở đây vậy? Cpk có vẻ không thực tế ở mức 42,68, đường "phù hợp" thì cao và hẹp, và các thanh trên biểu đồ đều bị đập xuống. Tuy nhiên, nếu chúng ta sử dụng chính dữ liệu đó để tạo biểu đồ bằng menu Biểu đồ, chúng ta thấy mọi thứ trông không đến nỗi tệ:
Vậy điều gì giải thích cho kết quả kỳ lạ của phân tích năng lực?
Lưu ý rằng biến thiên 'trong nhóm con' của kết quả đầu ra năng lực được biểu thị bằng đường nét đứt cao ở giữa biểu đồ. Đây là StDev (Trong nhóm con) được hiển thị ở phía bên trái của biểu đồ. Biến thiên trong nhóm con là 0,0777 rất nhỏ so với độ lệch chuẩn tổng thể.
Vậy điều gì khiến biến thiên trong nhóm con lại nhỏ như vậy? Một biểu đồ khác trong Minitab có thể cho chúng ta câu trả lời: Capability Sixpack. Trong trường hợp trên, kích thước nhóm con là 1 và Capability Sixpack của Minitab trong Stat > Quality Tools > Capability Sixpack > Normal sẽ biểu diễn dữ liệu trên biểu đồ kiểm soát cho từng quan sát, một biểu đồ I:
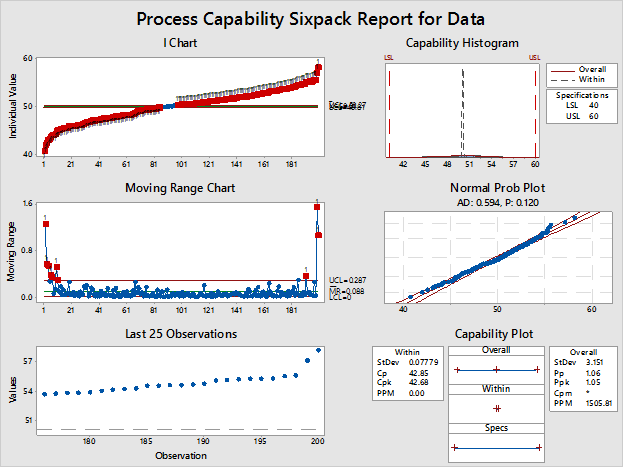
Hmmm...đây có thể là lý do tại sao trong khóa đào tạo Minitab , giảng viên của chúng tôi khuyên bạn nên sử dụng Capability Sixpack trước.
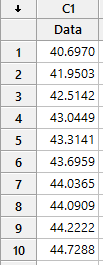
Trong biểu đồ Năng lực Sixpack ở trên, chúng ta có thể thấy các giá trị được vẽ riêng lẻ trên biểu đồ I cho thấy xu hướng tăng, và có vẻ như quá trình này không ổn định và không nằm trong tầm kiểm soát (như lẽ ra phải có đối với dữ liệu được sử dụng trong phân tích năng lực ). Xem xét kỹ hơn dữ liệu trong bảng tính, ta thấy rõ ràng dữ liệu được sắp xếp theo thứ tự tăng dần:
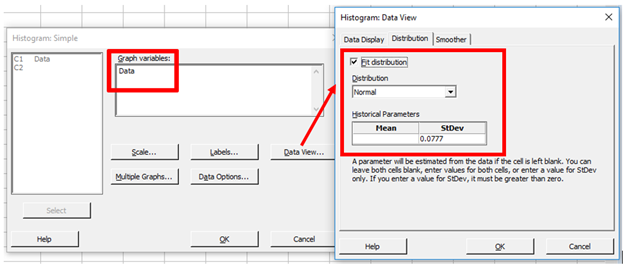
Do biến thiên trong nhóm con đối với dữ liệu không được thu thập trong các nhóm con được ước tính dựa trên phạm vi di động (trung bình khoảng cách giữa các điểm liên tiếp), việc sắp xếp dữ liệu khiến biến thiên trong nhóm con trở nên rất nhỏ. Với biến thiên trong nhóm con rất nhỏ, chúng ta thấy một đường khớp rất cao và hẹp biểu thị biến thiên trong nhóm con, và điều này đang "đập vỡ" các thanh trên biểu đồ histogram. Chúng ta có thể thấy điều này bằng cách tạo một biểu đồ histogram trong menu Graph và buộc Minitab sử dụng độ lệch chuẩn rất nhỏ (theo mặc định, biểu đồ này sử dụng độ lệch chuẩn tổng thể được sử dụng khi tính toán Ppk): Graph > Histogram > Simple , nhập dữ liệu, nhấp vào Data View , chọn tab Distribution , chọn Fit distribution và đối với Historical StDev, nhập 0,0777, sau đó nhấp vào OK và bây giờ chúng ta có:
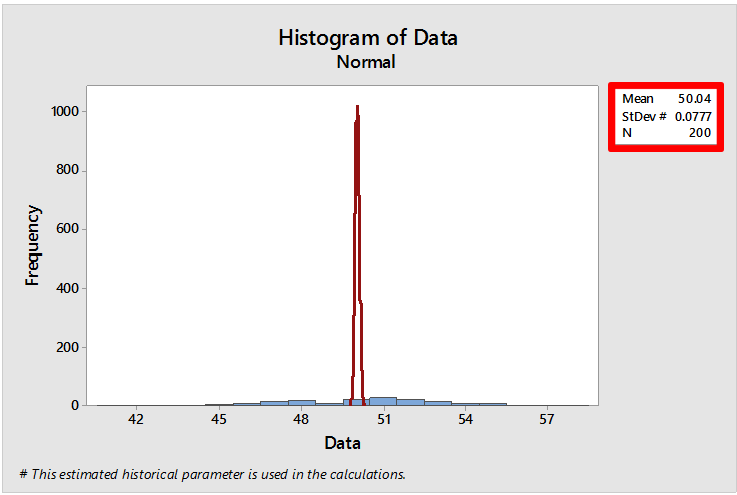
Bí ẩn đã được giải đáp! Và nếu bạn vẫn chưa tin, chúng ta có thể có được biểu đồ khả năng đẹp hơn bằng cách ngẫu nhiên hóa dữ liệu trước ( Calc > Random Data > Sample From Columns ):
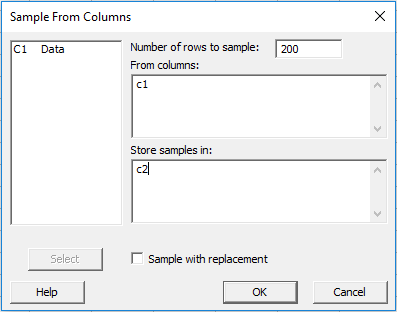
Bây giờ nếu chúng ta chạy phân tích khả năng sử dụng dữ liệu ngẫu nhiên trong C2, chúng ta sẽ thấy:
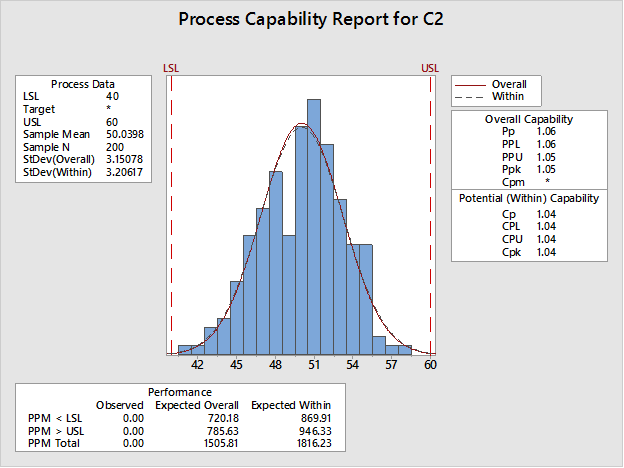
Lưu ý: Tôi không đề xuất rằng dữ liệu cho phân tích năng lực nên được sắp xếp ngẫu nhiên. Bài học rút ra là dữ liệu trong bảng tính nên được nhập theo thứ tự thu thập để đại diện cho sự biến thiên bình thường của quy trình (tức là dữ liệu không nên được sắp xếp ).
